
At Sparkbox, we love working alongside internal teams to share information and create great web products. So we were excited when we had this opportunity with an international distributor that needed to build an app for companies in a specific sales industry. Like many of our clients, this one prefers not to discuss their challenges and solutions publicly, but we’d still love to share what we’ve learned from this project.
Using this distributor’s new app, companies could glean insights from management system data and better track and improve their sales performance. But first, this distributor needed an MVP of their vision that they could pilot with a handful of companies. Because the first build was an MVP pilot, we approached the engagement from a lean perspective, building just enough to validate the idea while focusing on areas with the greatest business value. Throughout this case study, we’ll explain how we used data models constructed by the distributor’s data scientists (using the Domino Data Lab platform and Sails.js) to build their pilot application.
Architecture
Early discussions with this distributor made it clear that success would hinge on enabling their data science team to leverage Domino Data Lab’s capabilities. Domino Data Lab offers “an open, unified data science platform to build, validate, deliver, and monitor models at scale.” Models, in this world, equate to the results of data analysis over large bodies of data gathered from the companies within this industry. If we constructed the system well, we would enable the distributor’s data science team to provide companies with relevant metrics and cues to improve their own financial outcomes and better serve their customers.
In our experience integrating data analysis into applications, we’ve found Domino Data Lab unique in that it allows model results to be published seamlessly via native, RESTful web APIs with a tailored format or schema. This led our team to set three foundational principles for the architecture of this system:
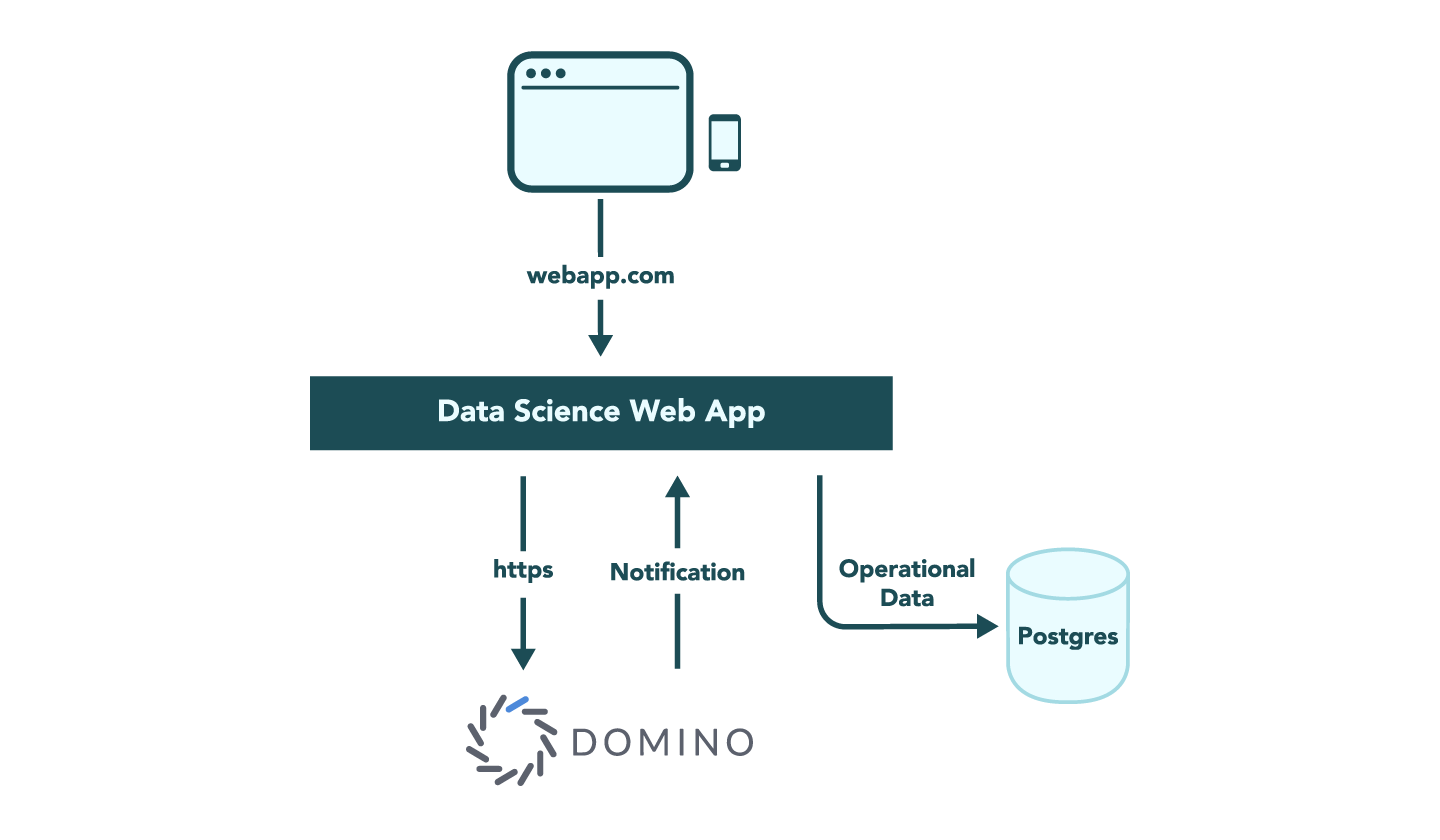
The web application layer should act primarily as a gatekeeper, authenticating, validating, and executing requests to Domino on behalf of users
Postgres should be prioritized for application operational data, such as user accounts, application preferences, and goal settings for the companies
Outbound payload transformations should be limited by the application layer
At a high level, you can think of the system as having three parts:
The web application built with Sails.js and deployed to Amazon Web Services (AWS)
The Domino Data Lab’s data science platform serving models to the web application via web APIs
A Postgresql database storing application operational data
Web Application as a Gatekeeper
The core responsibility of the web application is to authenticate users and make calls into the Domino Data Lab APIs on their behalf. For example, when a company’s employee logs in, they are greeted with a leaderboard, their status for a series of personal goals, personalized opportunities, etc.
By implementing the gatekeeper pattern in this part of the system, we gave the distributor’s data science team complete control of what’s presented. Data scientists can work with client management data to adjust models, and, in turn, improve the information provided to sales employees. That can happen all without new development efforts on the web application!
Finding the Seam
We knew that productivity was the key for the web application layer. We weren’t building anything groundbreaking at this layer. Having used Sails.js in the past, we knew it followed the productivity mantra of Ruby on Rails, allowing our team to build fast, well-designed web experiences quickly. Our team would be in charge of operational data such as user credentials, application metadata, and configuration preferences.
With the application layer in good hands and our principles clearly defined, we knew we had found the seam, as we like to call it, for these two parts of the system. Our tech lead and those responsible for the Domino models would work together to define contracts between our system.
Before each sprint began, our tech lead would work with the distributor’s data scientists to craft JSON payloads that would surface the data needed for the next area of work. Our tech lead would take Axure wireframes and Invision screens, annotate and decompose them into components and corresponding data, then, collaborating with the distributor’s team, determine a data structure that would fit yet be flexible.
With these payloads in hand, our development team could create data fixtures, static sample versions of the API, and see the application functioning in different scenarios! Our team was unlocked while the data science team built their end!
Attending to Assumptions
The greatest risk of working in parallel is accumulating assumptions. Our API contracts were built with both teams at the table. We agreed on their structure. That doesn’t mean they were correct. Only by integrating the two systems together would we know if our assumptions were correct, and that integration was just what our team worked toward. By creating fixture data from our contracts using different variations of data, we gained a level of confidence that the systems worked together.
From there, our goal was to continually deploy to a pre-production environment in Amazon Web Services (AWS) using Ansible. These environments had access to versions of the Domino endpoints. As Domino endpoints became available, Domino replaced our fixture data. As the distributor’s data science team completed model analysis, real model data replaced fixture data, bringing us closer and closer to an assumption-free level of “done.”
Working together as partners, we successfully created an architecture and process that will not only support this feedback-driven iteration but will also scale as the value of the app is proven and more companies sign on to the product.
